Here is the sequence of actions required to perform a technical website audit, in order to improve its quality and SEO.
With a crawler such as Hextrakt you get combined crawl data and analytics data, to perform relevant analyzes. This data is the raw material for technical SEO.
Server logs analysis for SEO, which consists in combining crawl data with Googlebot logs, will be discussed in another post. These are advanced optimization techniques, mainly for large websites (where the effects may be the most significant), which complement a crawl-based technical audit.
A technical audit is done in 3 steps:
- Crawling: the crawler follows every link in order to discover all pages and extracts useful data.
- Analyzing: data is processed in dashboards and indicators, allowing more in-depth analyzes, in order to identify the points to be corrected and the optimization levers.
- Optimizing: the errors have to be corrected in priority, then take care of the alerts (warnings) and the implementation of optimizations.

To come full circle and visualize all the required actions - for the technical part of SEO, we need to monitor the website performance: it is mainly about errors (404 errors, 500 ...), checking the effective crawl of googlebot, if the pages are indexed in Google, and organic traffic (from search engines).
Crawl: configuration and launch
The purpose of the crawl is to retrieve the data useful to SEO on all pages of the site. For a first crawl, we realize a first exhaustive crawl without limiting the depth or the number of URLs, in "HTML only" mode. In some special cases (e.g. sites built with Javascript frameworks), you need to run a crawl in Javascript rendering mode. It will get more data but will also be longer.
Note: The crawl of a website uses server resources in proportion to the crawling speed. For this reason, Hextrakt uses an adaptive asynchronous crawl technology to automatically find optimal crawling speed. Make sure you have permission from the site owner and inquire about the best time to crawl (web analytics reports can help).
Google APIs
Hextrakt allows you to combine technical data from the crawl with usage data from Google Analytics and Google Search Console to perform relevant analysis: some pages may be inactive (no users come from search engine results) or have no impressions (they are not displayed in search results).
If you have access to the Google Analytics and/or Search Console accounts used on the site to be audited, it is recommended that you set up the Google API connection to get more relevant information.
Analyzing
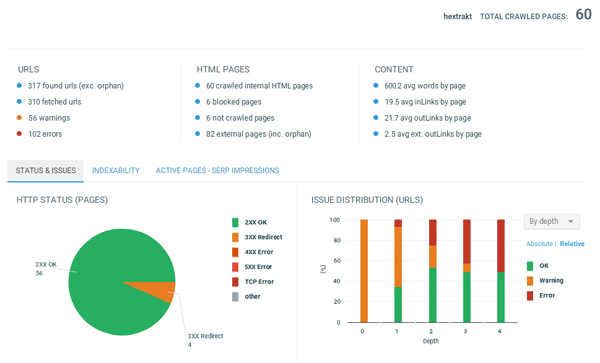
This report provides an overview of errors and their distribution, indexability issues (indexability tab), and active/inactive page ratios, with impression/without impressions ratios.
Segment data to make sense
Separating URLs into different meaningful subsets that have common characteristics makes it possible to compare, make sense, and more easily determine causal relationships.
Unless you are auditing a very small website, for relevant analysis it is therefore recommended to segment the URLs, in order to analyze the indicators by groups of similar pages, and to compare these groups with each other. A first categorization exists by default in hextrakt (as in most crawlers): by level (depending on the depth in the website's structure). Your own segmentation (templates, themes ...), specific to each project, will bring many optimization insights and help you to target the files to be corrected (templates).
The categorization of URLs is a good practice to implement at the beginning of the analysis; once the URLs will be categorized, they will remain for the following crawls (only new pages will need to be tagged if necessary).
Dive in the reports
Practice makes perfect... When you will have analyzed many crawl reports and acquired some reflexes, it will be easier for you to make recommendations of corrective actions. With experience, good ideas for optimizations come naturally.
Among the points to check in priority (mobile and desktop) :
- Is the ratio of pages without impression important? Some pages may not be indexed in Google. The important pages from an SEO point of view must be active (ie receive visits from the search engines).
- The directives: errors in the robots.txt file, errors in indexing directives (noindex tags) or in canonical tags, problems specific to mobile and multilingual sites.
- Redirections and errors (status codes 404, 500, 301) can be problematic if they are too many.
- Loading times
- Content structuring (title, Hn tags, structured data), access to these contents (depth, internal linking)
- Duplicate content
- ...
Successful SEO requires to use all available levers... Of course, many more points should be checked to perform a complete audit.
Optimizing
This crucial step consists in implementing the corrections or having them implemented, and checking that they are effective. By running a new crawl we can check if the errors have been fixed (menu "History & changes").
If the one who makes the recommendations is not the one who actually implements them, he should accompany the developers to facilitate their implementation. The purpose of all this is not to do an audit, but to improve SEO ...
Monitoring
A website is constantly evolving with the addition of new content, new features. It is essential to ensure that these new contents are well indexed and provide organic traffic, that the new features do not give rise to errors.
Tools:
Google analytics allows you to configure alerts: for example to receive an email in case of a drop in your organic traffic (visits from search engines).
Google Search Console: The Crawl> Crawl Errors menu allows you to identify site-level errors (DNS, server connectivity, robots.txt file) and URLs (URLs in error). The Exploration> Exploration Statistics menu can identify a drop in the number of pages crawled or, on the contrary, a sudden increase without having added new pages (googlebot could waste its crawl budget on useless URLs: spider trap).
Hextrakt: crawls at regular intervals make it possible to check the absence of new errors or variations in the analytics data by comparing to the previous crawl. In case of release of new features, updates of CMS or any changes that could impact the site technically, it is strongly recommended to launch a crawl.
Recommended reading: