Left part of the screen: collect data
Data type
In a web page (or in several web pages most of the time), JS Catcher is able to perform different kind of searches:
- pieces of data which have a similar nature (e.g. all products prices in an e-commerce website category page),
- pieces of data which have a different nature (e.g. product price, reviews count, product description... in a product page).
Locate data
You can look for data:
- in the whole page,
- in a single container,
- in a repeating container in the page.
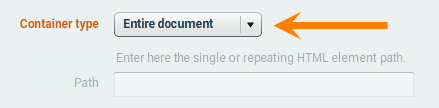
Most of the time you will keep the default setting: "Entire document". It is the case for example when you want to collect different types of data from a set of product pages.
Sometimes you will need to collect data of same type, e.g. all links to product pages in a category page. In that case JS Catcher will collect data inside each repeating block / HTML element in the page.
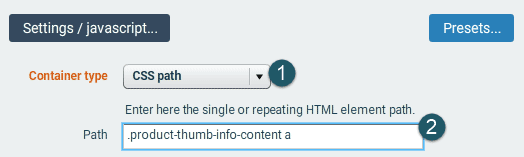
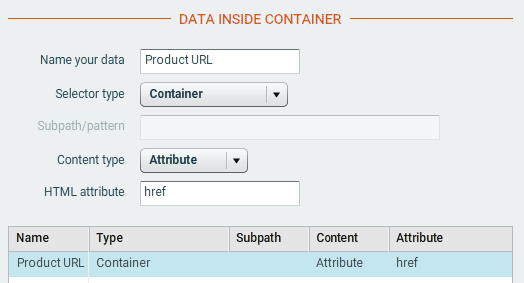
Let's indicate which data to collect in the container (click on "Add"):
Presets
You may want to save your settings in presets in order to reuse them easily. You can also export an share your presets (you may only save selectors, or both selectors and URLs to scrape).
Right part of the screen: list of URLs to scrape and results
Paste the URLs to scrape in the field "List of URLs", one URL per line.
In the results window, these three columns are displayed by default:
- line number,
- URL,
- URL status (OK or not, redirect, etc...).
The other columns display data for a particular URL: each line (path) in the left window will be displayed in a column of the right window's table.